
The missing blogging platform for hackers
Blog the richest content, with the least effort.
Take a Tour-

Revolutionary Editor
Logdown supports GitHub Flavored Markdown, LaTex and is compatible with Octopress syntax, also provides in-editor preview with best user experience.
-

Powerful Image Uploader
Instinctive interface for uploading images. Never feel that easy blogging with pictures. Drag & Drop local files or importing from Flickr, Facebook, Instagram…
-

Compatible syntax & urls
No complex setting or steps for importing old blogs. Support Wordpress, Octopress syntax and urls. It's also easy to export blogs if you decide to leave us.



Revolutionary Editor with Powerful features
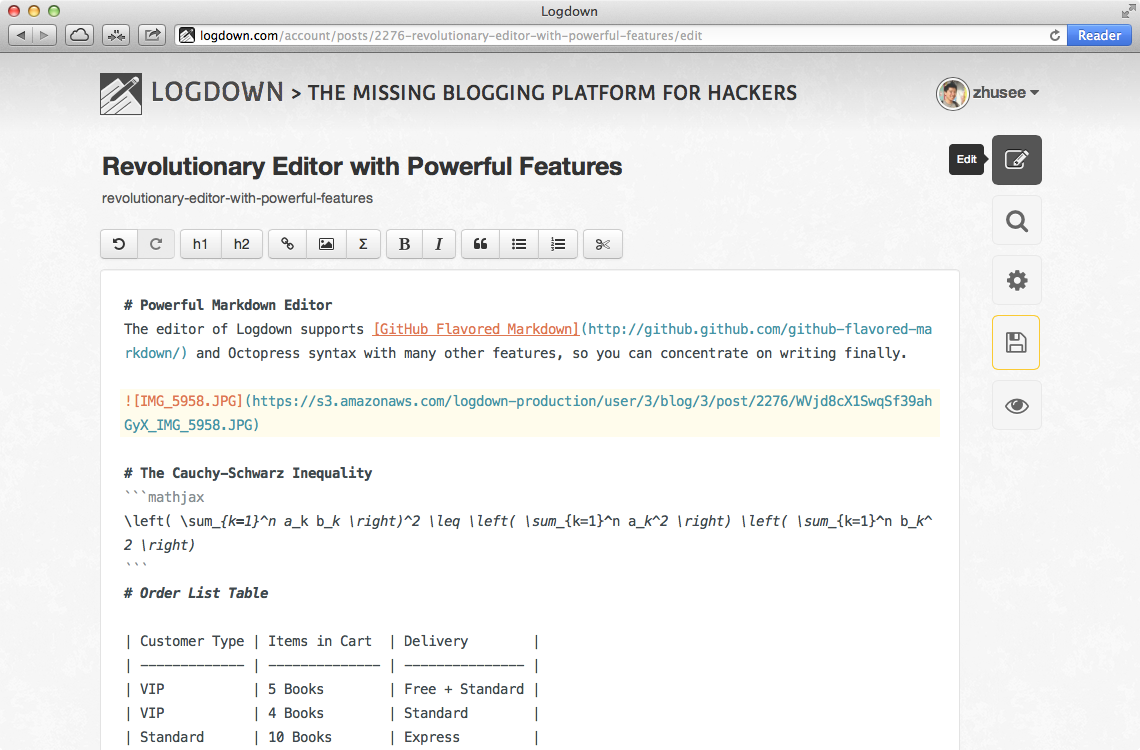
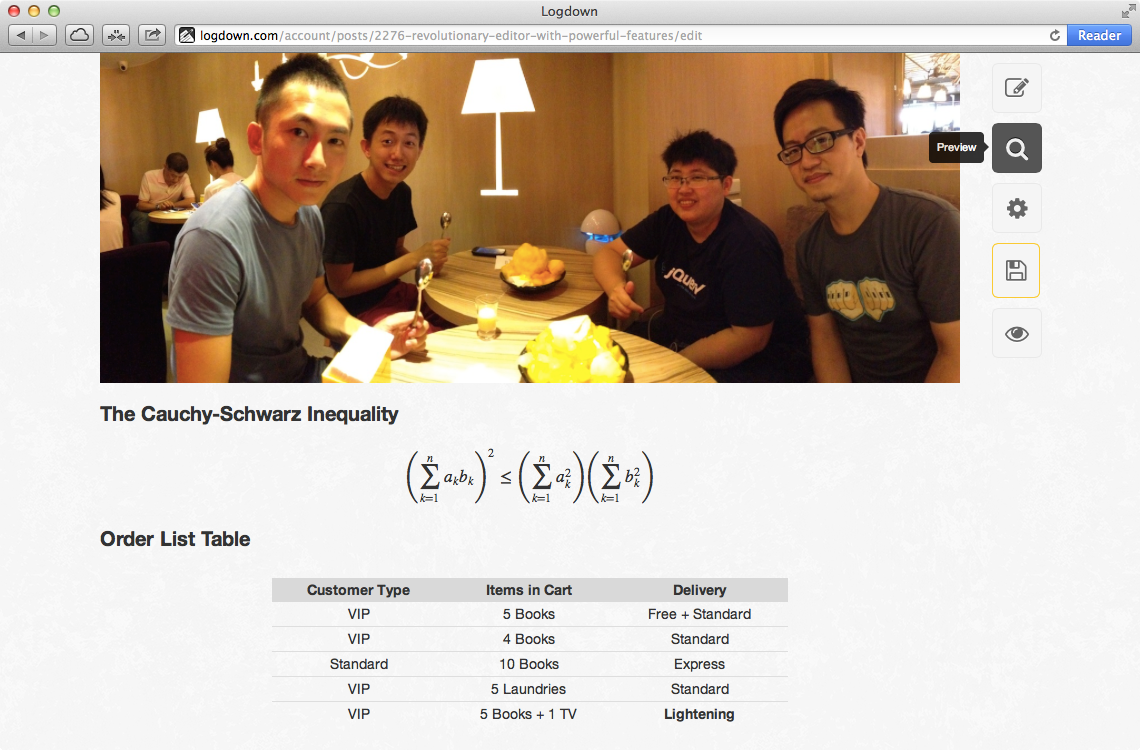
Supports GitHub Flavored Markdown, LaTex in-editor preview, with the most handy image uploading interfaces. Never feel that easy blogging with code blocks, tables, and even math equations. Auto detect changes and enable prevent window closing to save your draft thoughts in last seconds. Try the Demo now.
Features done right
-

Custom domains
Your domain is your personal brand. Logdown let you host blog under whatever domain you want.
-

Painless import / export
Quick and easy import from major blogging platforms. Painless export - if you choose to leave.
-

Social integration in seconds
Comment system powered by Disqus, you can transfer previous comments with every post. Auto generating detailed OpenGraph info.
-

Backup services
We backup your blog more than six times a day for peace of mind. Any concerns? We can answer your question anytime.
Be the first to try out Logdown.
Get Started Now